程序的生成与运行
这篇文章里,我将介绍一个程序从源码到内存中运行的整个过程。这涉及到很多方面的知识,如有错误还请读者斧正。
高级程序设计语言、汇编语言、机器码
在英语中有a-z这26个字母,一个孩子从最基本的字母开始学起。字母本身没有什么含义,但当它们组合起来,就成了可以描述世界的单词与句子。计算机是一个笨一点儿的孩子,由于它构造的特点,只能认识0和1这两个“字母”,0和1的组合则构成了计算机的“句子”。比如,指令0000就代表加载操作。在计算机发展的初期,程序员就使用这样0和1组成的指令进行编程,这些0和1的组合被称作机器码。
虽然机器码对于计算机很容易理解,但是程序员却很难记住,一堆0和1的组合难免看花眼。因此,助记符被发明了出来,比如人们约定用汇编指令LOAD代表机器指令0000。含有人类可理解语义的助记符减轻了程序员的负担。这些助记符就是汇编语言,用汇编语言写的程序被称为汇编程序,将汇编程序转换为机器码的程序叫做汇编器。
可是,当程序变得越来越复杂后,人们发现汇编语言还是不够简洁—它还是太符合计算机的思维模式而非人类的思维模式了。假如我想让内存中的一个变量加1,对人的思维来说是一步操作;在汇编中则意味着从内存中取出数据放到寄存器里,对寄存器进行加1操作,将数据重新写入内存。要是执行复杂的计算、编写繁琐的分支语句,对应的汇编指令就更多了。
因此,高级程序设计语言出现了,它更符合人类的思维模式。上面所说的加1操作,一条指令就可以搞定了。高级程序设计语言也有很多种类,常见的分为编译型、解释型和半编译半解释型语言。这种分类的依据是它们执行的方式。但是,这是较为传统的分类方式,网络上也有一些讨论认为这样的分类方式已经有点“力不从心”了,详见:https://www.zhihu.com/question/19608553。不过,本文的介绍基于编译型的C语言。
预处理、编译、链接、汇编
这一部分介绍一个程序源码是如何转换成能够运行的机器码的,按照顺序分为预处理、编译、汇编、链接。
预处理
预处理是转换的第一步,主要的处理规则如下:
-
将所有的“#define”删除,并且展开所有的宏定义。
-
处理所有条件预编译指令,比如“#if”、“#ifdef”、“#elif”、“#else”、“#endif”。
-
处理“#include”预编译指令,将被包含的文件插入到该预编译指令的位置。
-
删除所有的注释。
-
添加行号和文件名标识,以便于编译时编译器产生调试用的行号信息以及编译产生编译错误、警告时能够显示行号。
-
保留所有的#pragma编译器指令,因为编译器要使用它们。
— 参考自《程序员的自我修养》
预处理的过程比较固定,下一步的编译则有很多值得关注的地方。
编译
一个完整的编译过程包括前端、中端和后端的处理。前端包括词法分析、语法分析、语义分析,和编程语言相关性较大。中端包括程序分析和代码优化,注重可重用性。后端则进行代码生成,和代码要运行的平台有关。
词法分析的功能是将一个字符序列分解成一个个编程语言支持的TOKEN。例如,int a = 1会被分解为4个TOKEN:“int”、“a”、“=”、“1”。当然,真正的词法分析器还要对这些TOKEN进行标注,类似于(“类型定义”,“int”)、(“变量”、“a”)、(“赋值符号”,“=”)、(“字面量”、“1”)。词法分析器可以通过有限自动状态机实现。
语法分析读取词法分析的结果进行分析。语法分析有自顶向下的分析、自底向上的分析,不过这里也不会去写那复杂的一套。如果让我简单地解释语法分析是什么,我觉得可以这样说:语法分析就是判断词法分析得到的TOKEN序列是否符合编程语言的产生式规则。什么是产生式规则?比如int_var -> int_var op int_var(其中int_var代表整型变量,op代表运算符)就是一个产生式规则,它意味着两个整型变量的运算结果可以归约为一个整型变量。所有的产生式规则定义了一个编程语言的编程规范。
值得一提的是一个十分有用的数据结构:抽象语法树(AST,Abstract syntax tree),它是一个文件的语法结构的描述,在安全研究中应用广泛。比如,要fuzz一个js引擎,使用AFL可不行,它的随机变异破坏了JavaScript的语法规范,在js引擎中根本走不远;因此,可以获得规范的JavaScript文件的AST,在叶节点上进行变异,以此生成符合JavaScript语法规范的输入。
语义分析分析代码的语义错误。以如下代码为例:
void func() {
return 1;
}
void是合法的返回值类型,return 1也是合法的返回语句,但是两个在一起就有了语义错误。其实语义错误也有静态语义错误和动态语义错误,像这个是编译期就可以检查出来的静态语义错误。如果有一个表达式出现了除0的问题,就是动态语义错误,只有运行时才能发现。
经过了上述的词法分析、语法分析、语义分析,就进入了编译的中端:程序分析与代码优化。在这一个阶段,我们大有可为。前面我们提到了中端注重可重用性,这一点在LLVM编译套件上体现的淋漓尽致。前端Clang支持C、C++、Objective-C、Objective-C++,但是在中端分析时,它们统一被转换成中间代码IR。这样,一套程序分析与代码优化程序可以应对不同的编程语言。
中端主要做的事情就是代码优化,而这种优化是基于对程序的分析。常见的程序分析方法有控制流分析、数据流分析、指向分析、过程间分析。这一部分内容很多,我只简单描述描述,以感受到中端的作用为主要目的。
在代码中,for、while会引入循环。由于循环会执行很多次,因此循环部分的优化很重要。要优化循环当然要先找到循环,通过控制流分析就可以做到。控制流图描述了基本块之间的流向,通过控制流图中的回边和特定的算法,就可以求得循环。在找到循环后,可以将循环不变式外提,提高程序效率。
for (int a = 0; a < 10000; ++a) {
b = 1;
c = b + a;
}
// 循环不变式外提示例,(其实还可以进一步优化为c = 1 + a)
b = 1;
for (int a = 0; a < 10000; ++a) {
c = b + a;
}
这是代码优化的一个例子,展现了中端的作用。控制流分析外,数据流分析中常见的还有可用表达式分析、活跃变量分析、到达-定值分析等。编译的后端是代码生成器,它读取代码的中间表示和符号表信息(存储中间表示的变量信息),生成目标程序。代码生成器要处理存储管理、指令选择、寄存器分配、计算次序选择等问题来充分利用目标机器的资源。
链接
在使用程序设计语言进行开发时,可能要使用一些封装好的库,因此源码中也就有了对这些库的引用。完成上一步的编译后,这些引用还是“孤立”的状态,而将这些引用和它们的功能实现关联起来正是链接这一个步骤要做的事情。
库分为静态库和动态库,静态库常以.a(Linux下)和.lib(Windows下)结尾,动态库常以.so(Linux下)和.dll(Windows下)结尾。相对应的,链接也分为静态链接和动态链接两种,它们的区别是是否在生成可执行文件时将被引用的库文件包含到生成文件中。静态链接将其包含进来,动态链接则等到程序运行时再进行相应库的装载。
静态库其实就是很多目标文件的集合,在静态链接时,会从静态库中筛选出被引用的目标文件。**静态链接有三步:1. 空间与地址分配,2. 符号解析,3. 重定位。**在空间与地址分配阶段,链接器扫描输入的文件(包含源文件和被引用的目标文件),获取它们的段信息和符号表信息。不同输入文件的同一类别的段被合并在一起,符号表也合并成了一个全局符号表。有了所有输入文件的段信息,各个段在虚拟内存的地址就确定了,因此可以根据这些确定了的地址进行全局符号表的更新。符号解析就是将分布在不同输入文件中符号的引用和定义关联起来,检查有没有什么错误。符号解析的执行过程如下图所示。

符号解析完成后,执行重定位操作。需要重定位是因为在编译时,编译器无法确定从外部引用的符号的地址,但是完成了空间与地址分配后,这一地址就确定了。因此,重定位阶段读取重定位表获得重定位入口,并查询全局符号表进行相应的地址修正。
上面介绍了静态链接的过程,不过,它有如下几个缺点。首先,每一个程序都要将静态库中自己使用的目标文件包含进来,这样不利于节省空间。而且,假如程序更新了某一个静态库,则整个程序都得重新链接生成。动态链接则能解决这些问题。
动态链接库本身不被包含到生成的可执行文件中,它只有当程序加载时才进行加载。链接器通过输入的动态库的符号信息得知源文件中哪些符号是动态符号,不对其进行重定位,而是留到装载时再进行。不过这里有一个问题,动态库不像静态库一样在装载运行前参与了空间与地址分配、重定位,拥有一个固定的虚拟地址;那么它被装载后指令中地址相关的值怎么确定的呢?显然,在编译时固定动态库的虚拟地址是不行的,当动态库数量较多时地址难免冲突,管理复杂。常用的解决办法有两个。一是装载时进行重定位,每个程序根据自己的情况对动态库分配不同的虚拟地址,但是动态库的物理地址是固定的。不过这样有一个缺点,进行重定位需要修改指令,为了防止当前程序的修改对其他程序造成影响,需要产生一个动态库的副本,这样就影响了动态库节省空间的好处。还要一种方法是使用地址无关代码(PIC,Position-independent Code),通过特殊的技术使得指令寻址不会因装载地址的变化而变化。
汇编
汇编的过程将汇编代码转换为机器可以之间执行的机器码。值得一提的是反汇编常见的两种算法,线性扫描反汇编与面向代码流的反汇编算法。了解反汇编算法的假设(比如线性扫描假设所有的都是指令,使得数据有可能被反汇编成指令)是对抗反汇编技术的前提。
程序的加载
在计算机发展的早期,程序的加载简单粗暴,就是直接把程序加载到内存中,且程序直接使用内存的物理地址。可是这样做有几个明显的问题。如果程序本身比内存还要大怎么办?程序直接使用内存的物理地址,如果加载的位置不一样,是不是很多地址相关的指令都得修改?直接使用物理地址,不同程序之间没有很好的隔离,是否更容易产生安全问题?
为了缓解这些问题,现代操作系统大都采用了虚拟内存机制与分页机制。
虚拟内存相当于在进程和物理内存之间增加了一个中间层,进程直接根据虚拟内存地址寻址,集成在CPU中的内存管理单元(MMU,Memory Management Unit)再将该虚拟地址转换为物理地址。这样,程序每次加载时实际的物理地址可能不同,但是它面向的虚拟地址都是固定的。需要注意的是,虚拟内存仅仅是一个抽象的概念,并不是真正有那么一块内存被称作虚拟内存,它是物理内存经过地址转换后的另一个称呼。
分页机制则利用了程序的局部性原理—程序在执行时访问的区域往往限于某一局部。在程序执行时,没必要把它全部加载到内存中,只要把它需要的部分加载进来即可。并且,由于其运行时的局部性,这种加载方式也不会造成太大的额外开支。这样做明显的好处是节省了内存开销。将程序的一部分加载到内存中,这个一部分代指的粒度,就是一个页。虚拟内存的页成为虚拟页,物理内存的页称为物理页。
下面通过一个简单的过程介绍,看看虚拟内存和分页机制是如何作用于程序加载的。ELF文件和PE文件加载过程不同,下面的过程仅是一个抽象的、高层的介绍。
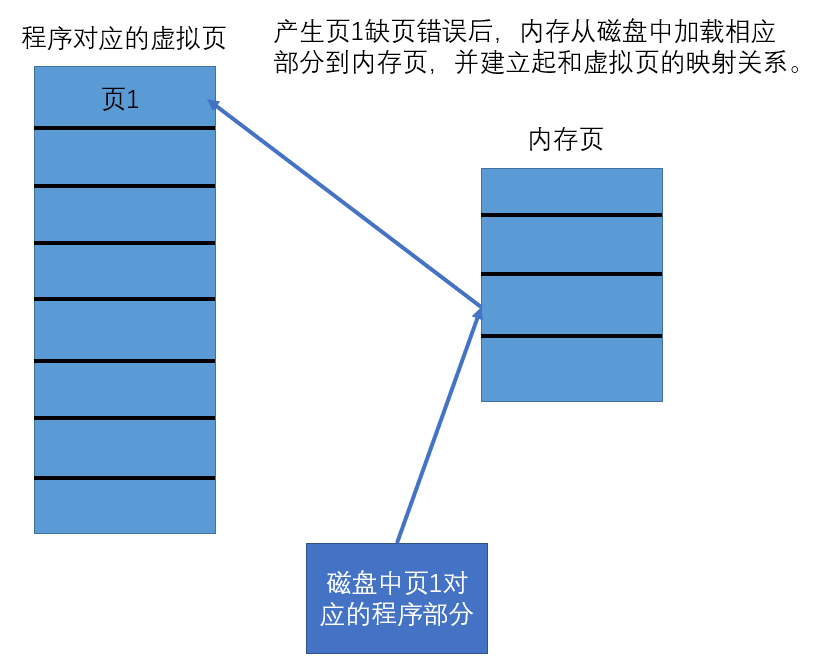
当一个程序准备加载运行时,首先操作系统要新建一个数据结构,来保存虚拟页和物理页之间的对应关系。但是,仅仅创建该数据结构,并对其进行实际的填充—因为还没有实际分配物理内存,物理页怎么填?然后,操作系统读取要运行程序的头部,其中包含了该程序的段信息,操作系统将程序和虚拟页对应起来。最后,将指令寄存器设置为该程序的入口地址,开始执行。
前面所说的三步并没有实际将程序从磁盘装载到内存,只是设置了一些数据结构。因此,开始执行时,进程会遇到一个页错误—程序所需部分对应的虚拟页并没有相应的物理页。这时,操作系统将计算出所需部分在程序中的偏移,将其加载到物理页中,然后建立起该物理页与所需部分对应虚拟页的映射关系。这样,再次访问该部分就不会产生页错误了,如下图所示。
从反汇编看程序的运行
使用OllyDbg对二进制程序进行动态调试,结合反汇编代码,可以对程序的运行有较完整的了解。在这之前,首先要进行一些基本的介绍。一个程序加载到内存中后成为一个进程,它的内存空间大致可以分为四块:
- 代码区:存储被装入执行的二进制代码。
- 数据区:存储全局变量。
- 堆区:进程可以在此动态的请求内存。
- 栈区:动态地存储函数之间地调用关系。
本文着重关注栈区的行为,栈在内存中由高地址向低地址扩展,如下图所示。

每一个被调用函数在栈中拥有一个栈帧,其中存储了函数的局部变量,还有一些用来协调函数之间互相调用的数据,还有一些异常处理等相关数据,暂时不考虑。对于当前栈帧,操作系统使用ESP(extended stack pointer)来表示栈帧的顶部,使用EBP(extended base pointer)来表示栈帧的底部。
分析下面的代码段:
#include "stdio.h"
void sub_func(int a, int b) {
int c = a + b;
printf("%d\n", c);
}
int main(void) {
int x = 1;
int y = 3;
sub_func(x,y);
return 0;
}
前面说了每一个被调用函数有一个栈帧,那么当main函数调用sub_func函数时,是如何产生sub_func函数栈帧的?参数是如何从main被传递给sub_func的?sub_func执行结束后又是如何返回到main中的?接下来通过OllyDbg对其生成程序进行动态调试,来分析这些问题。
将程序停止在call sub_func指令处,call指令将在下一步运行,如下图。可以看到,参数1和3被放到main函数栈帧的顶部。这就是参数传参的方式,在执行call指令前,将参数压入栈。

接下来,执行call指令并step-into sub_func函数,这时sub_func里的指令还没有执行,如下图。可以看到,栈中新压入了一个数据,这是call指令下一条指令的地址,也就是sub_func函数执行完的返回地址。call指令其实有两个作用,一是将返回地址压栈,二是使eip指向被调用处。
对于sub_func函数的前三条指令,push ebp将main函数的栈帧基地址保存在栈中,方便sub_func执行结束后恢复main函数的栈帧。mov ebp, esp是将main函数的栈帧顶部作为sub_func函数的栈帧底部(esp指向处保存了main函数的ebp,因此新sub_func的ebp其实指向了保存main的ebp的地方),sub esp, 28扩充sub_func的栈帧(注意栈向低地址增长),这样sub_func函数的栈帧就形成了。

执行上述的三条指令,可以看到执行后ebp与esp的变化,如下图,现在它们指向sub_func的栈帧了。

当sub_func执行结束后,leave指令和retn指令负责整理栈并返回main函数。leave指令等价于mov esp, ebp; pop ebp。还记得之前说sub_func的ebp其实指向了main的esp(也是保存main的ebp的地址)吗?mov esp, ebp将栈顶重新设置为main的esp,也就是保存main的ebp的地方,然后pop ebp将main的ebp恢复。执行完leave指令,esp指向了返回当初call指令压入的返回地址,下图展示了执行完leave指令栈的变化。

接下来,retn指令从栈中弹出该返回地址,并将其填充到eip来跳转回main函数。这样,调用sub_func函数的一整个流程就完成了。总结一下函数调用流程:
- 参数入栈(调用者完成)
- 返回地址入栈(调用者的call指令完成)
- 代码跳转至子函数(调用者的call指令完成)
- 栈帧调整(子函数完成,保存调用者栈帧并生成自己的栈帧)
函数返回流程:
- 恢复上一个栈帧(子函数完成,leave指令)
- 弹出返回地址并跳转回调用者(子函数完成,retn指令)
写到这里差不多就结束了,这就是一个程序从生成到运行的过程,总结下来感觉受益良多,日后有新的感悟再进行修正与补充!