Paper Note | Meaningful Variable Names for Decompiled Code: A Machine Translation Approach
Publication: ICPC 2018
论文摘要
When code is compiled, information is lost, including some of the structure of the original source code as well as local identifier names. Existing decompilers can reconstruct much of the original source code, but typically use meaningless placeholder variables for identifier names. Using variable names which are more natural in the given context can make the code much easier to interpret, despite the fact that variable names have no effect on the execution of the program. In theory, it is impossible to recover the original identifier names since that information has been lost. However, most code is natural: it is highly repetitive and predictable based on the context. In this paper we propose a technique that assigns variables meaningful names by taking advantage of this naturalness property. We consider decompiler output to be a noisy distortion of the original source code, where the original source code is transformed into the decompiler output. Using this noisy channel model, we apply standard statistical machine translation approaches to choose natural identifiers, combining a translation model trained on a parallel corpus with a language model trained on unmodified C code. We generate a large parallel corpus from 1.2 TB of C source code obtained from GitHub. Under the most conservative assumptions, our technique is still able to recover the original variable names up to 16.2% of the time, which represents a lower bound for performance.
解决的问题与创新点
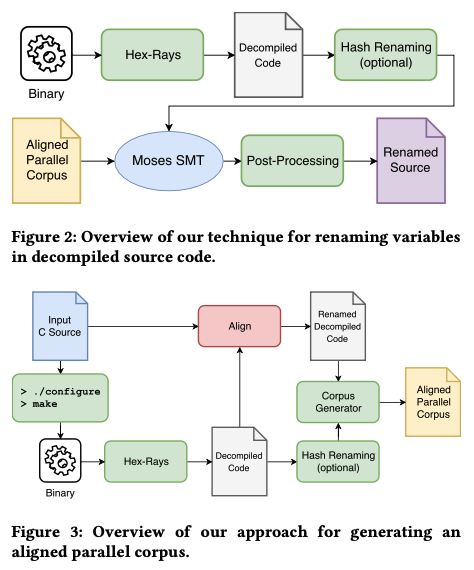
这篇文章采用SMT(Statistical Machine Translation)技术,将反编译结果中无意义的变量名“翻译”为有意义的变量名,从而提高反编译结果的可读性。使用SMT需要一个对齐的数据集,保护翻译前后被翻译后数据的对应。然而,反编译结果的代码风格与包含有意义变量名的源代码差异很大,很难直接产生对齐数据集,作者着重研究了如何将源代码中的变量名赋给反编译结果中的变量,进而形成对齐数据集。
具体地说,作者提出了A、B、C三种方案来实现变量名的映射。A将该问题看成assignment problem,使用Hungarian algorithm;B、C将问题看成sequence alignment algorithm,采用Needleman-Wunsch algorithm。作者还提出了两个启发式规则作为映射结果的衡量,一个是usage signature,考虑某变量被用在了哪些表达式中;一个是function signature,考虑某变量被用在了哪些调用的参数某位置和返回值赋值中。
在workflow还有一个hash renaming,它的作用是“标准化”反编译结果中的变量名。因为反编译器分配的变量名反正是没有意义的,不如就根据变量的类型、上下文信息等给变量重命名,让反编译的变量名包含一些有效信息,来提高翻译的准确性。
声明的贡献
-
We show that it is possible to automatically generate an aligned parallel corpus between natural C code and decompiled C code, using simple alignment heuristics;
-
We train and evaluate an SMT model that can suggest natural variable names in decompiled C code, based on the open-source SMT toolkit Moses, commonly used in natural language translation. This demonstrates that SMT techniques can be used for information recovery in source code even when the difference between the original and the transformed source code is more complex than simple α-renaming of variable names.
总体方法