Paper Note | DIRE: A Neural Approach to Decompiled Identifier Naming
Publication: ASE 2019
论文摘要
The decompiler is one of the most common tools for examining binaries without corresponding source code. It transforms binaries into high-level code, reversing the compilation process. Decompilers can reconstruct much of the information that is lost during the compilation process (e.g., structure and type information). Unfortunately, they do not reconstruct semantically meaningful variable names, which are known to increase code understandability. We propose the Decompiled Identifier Renaming Engine (DIRE), a novel probabilistic technique for variable name recovery that uses both lexical and structural information recovered by the decompiler. We also present a technique for generating corpora suitable for training and evaluating models of decompiled code renaming, which we use to create a corpus of 164,632 unique x86-64 binaries generated from C projects mined from GITHUB. Our results show that on this corpus DIRE can predict variable names identical to the names in the original source code up to 74.3% of the time.
解决的问题与创新点
文章基于软件的natural特性(software is natural, i.e., programmers tend to write similar code and use the same variable names in similar contexts),基于上下文环境对反编译的结果中的变量名进行重命名,来提高反编译结果的可读性。作者认为之前的方法存在如下缺陷(1)直接依赖二进制语义,忽略了反编译器提供的丰富信息;(2)依赖于反编译器词法输出的顺序关系,而缺少了对结构关系的考虑。因此,作者提出DIRE,同时使用反编译器内部对二进制的AST表示(反编译器提供的结构信息)和反编译器的词法输出两者提供的上下文信息来对变量名进行预测与重命名。
声明的贡献
-
Decompiled Identifier Renaming Engine (DIRE), a technique for assigning meaningful names to decompiled variables that outperforms previous approaches.
-
A novel technique for generating corpora suitable for training both lexical and graph-based probabilistic models of variable names in decompiled code.
-
A dataset of 3,195,962 decompiled x86-64 functions and parse trees annotated with gold-standard variable names.
总体方法
DIRE总体遵循encoder-decoder的结构,使用LSTM和GGNN作为encoder,LSTM作为decoder。LSTM用于提取反编译器词法输出的顺序关系,GGNN用于提取AST的结构关系。
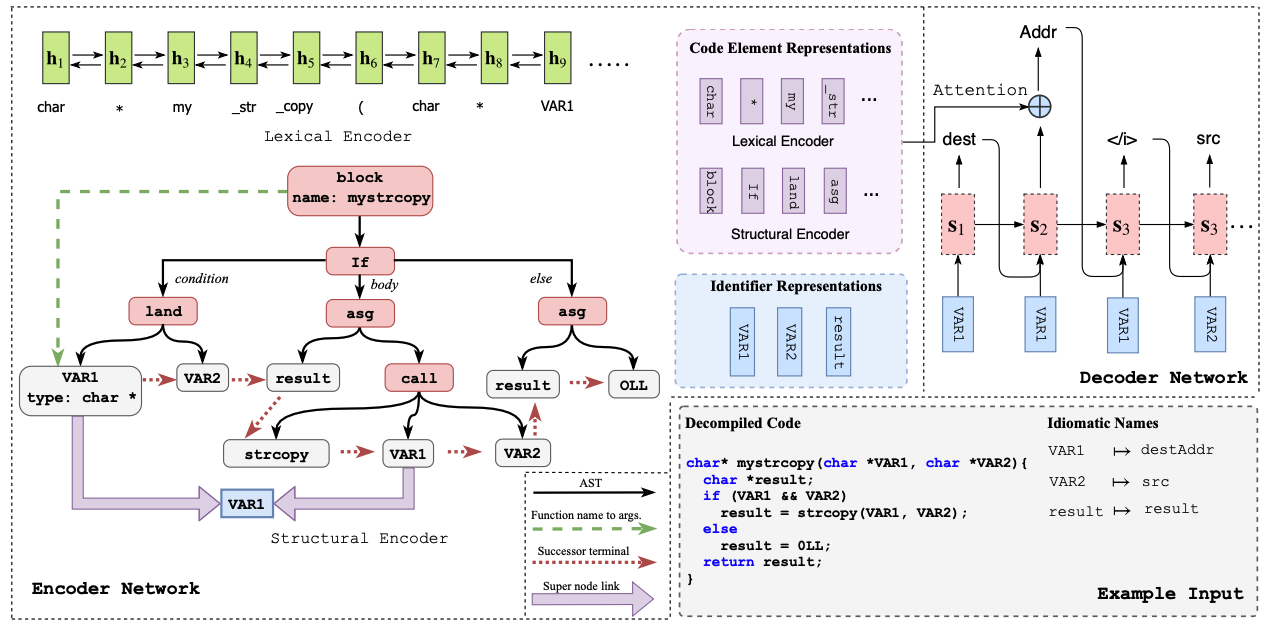
此外,作者介绍了生成数据集的方法。基本思路是将含有符号信息的二进制进行反编译,和将该二进制strip后的反编译结果进行比对,从而找到strip后的反编译结果中二进制应当的命名。但是,含有符号信息的和strip后的反编译结果的程序结构可能不同(如一个用for一个用while),符号信息也会影响到反编译产生的additional variable(指源程序中不包含的变量)的数量;这不是一个简单的一一对应关系。基于此,作者提出根据变量被使用时指令的地址偏移形成签名,来对两个反编译结果中的变量建立对应。这是因为虽然反编译结果不同,反汇编结果应该是差不多的,同一个变量在有/无符号信息的二进制里面被指令使用时,指令的地址应当是相同的。
其它
- 作者衡量预测出的变量名与ground truth是否一致时,使用了最小编辑距离进行评价。
- DIRE忽略对反编译结果中additional variable的命名;也许是因为在上述评价指标下,这些变量的ground truth不好找。